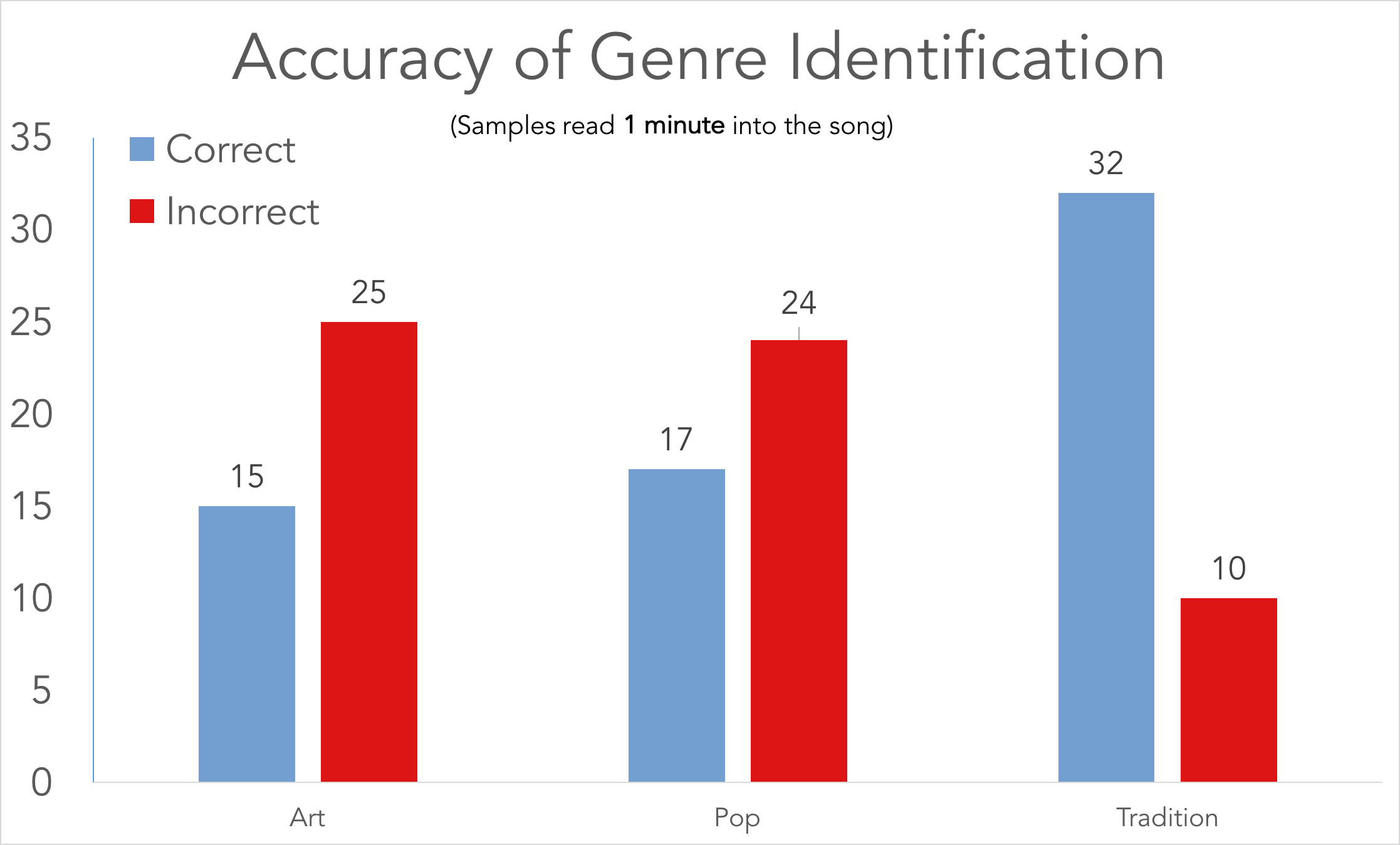
Overfitting proves to be a significant problem - the graph at right shows that the network (run using the '120.minute.0.0' setup) was able to identify traditional music fairly well, but further examination of the data shows that of the incorrect identifications in art and pop, they were mostly sorted into traditional.
Using a balanced sample set is quite important - an earlier test, using the entire iTunes library of one of our researchers (which heavily featured popular music), yielded extreme overfitting to popular music.
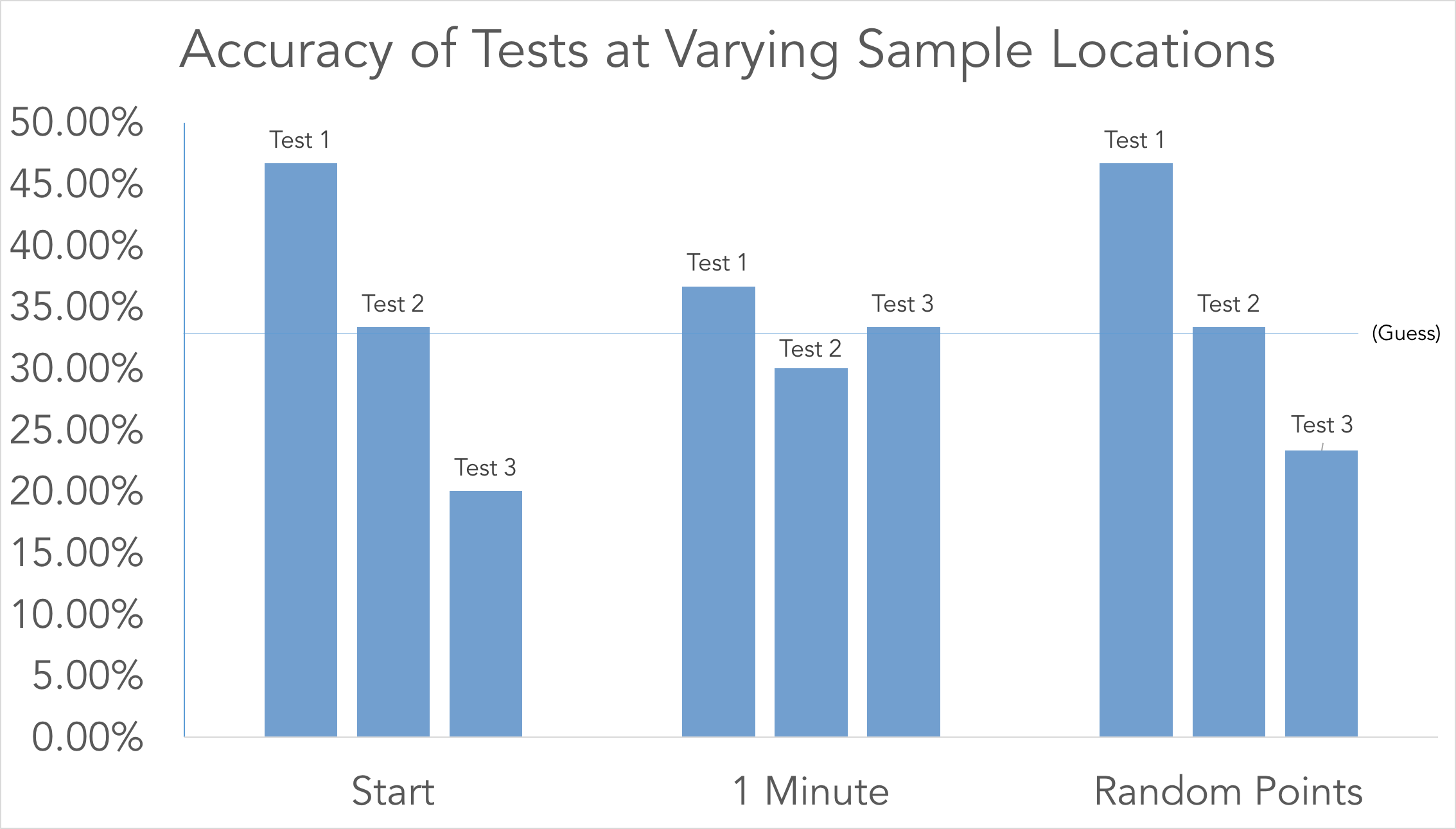
In comparing which sample locations worked best, we found that using random points throughout the song and reading the first 15 seconds of the song yielded strikingly similar results, while a contiguous 15 seconds starting at 1 minute into the song was far more accurate, if not as precise.